Author : Daeguen Lee
(Any action violating either copyright laws or CCL policy of the original source is strictly prohibited)
얼마 전 백엔드 구조를 중심으로 현대의 CPU에 대해 알아 보았습니다.
(현대 CPU의 구조 강좌 <백엔드 편> ☞ 여기)
이번 강좌에서는 그때 설명하지 않고 남겨둔 프론트엔드에 대해 간략히 알아보도록 하겠습니다.
우선 저번 강좌에서 처음 등장했던 그림을 다시 한번 보시겠습니다.
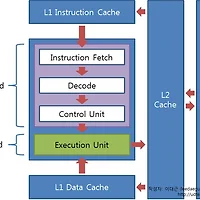
오늘날의 컴퓨터는 그 외형과는 별개로, 공통적으로 위와 같은 구조를 가집니다.
저장 장치에서 명령어와 데이터를 인출(Fetch)해서 내부적으로 처리 가능한 포맷으로 변환(Decode)한 뒤
제어 유닛이 명령어를 정렬해 수행 유닛에 전달해 주고 수행 유닛이 이를 처리하는 것.
이것이 현대의 컴퓨터가 작업을 처리하는 방식입니다.
저번 강좌에선 연두색(수행 유닛)에 해당하는 백엔드의 구조만을 살펴보았는데
이번 강좌에서 다룰 부분은 바로 연보라색 상자 안에 해당하는 '명령어 인출-디코드-제어 유닛' 부분입니다.
실질적으로 계산이 일어나는 수행 유닛(백엔드)은 CPU 성능에 절대적으로 중요하지만
백엔드가 아무리 빨라도 프론트엔드가 명령어를 제때 공급해주지 못하면 소용이 없습니다.
1999년 AMD 애슬론의 등장과 함께 현대 CPU의 백엔드는 충분한 대역폭을 갖게 되었고
이에 따라 오늘날의 CPU의 성능 차는 대개 프론트엔드에 의해 갈리게 됩니다.
또한 그 중에서도 파이프라인의 가장 많은 스테이지를 점유하는 디코딩 과정은 특히 중요합니다.
따라서 오늘은 디코더 구조를 중심으로, 프론트엔드의 구조에 대해 알아보겠습니다.
1. Intel P5 Microarchitecture



인텔 펜티엄은 데스크탑용으로 처음 수퍼스칼라 구조를 채택해서 유명한 CPU입니다.
펜티엄의 프론트엔드와 백엔드 사이에는 순차 제어 유닛이 놓여 있습니다.
이름이 말해 주듯 이 제어 유닛은 프론트엔드에서 디코드한 명령어를 "순차적으로" 백엔드에 전달하는데,
최대 2개까지의 명령어를 동시에 처리 가능한 펜티엄의 수퍼스칼라 백엔드의 장점을 살리기 위해서는
명령어들을 최대한 동시에 많이 처리할 수 있도록 조합해서 전달해 주는 것이 중요합니다.
하지만 순차 제어 유닛은 이러한 조합을 만들어내는 데 제한적일 수밖에 없습니다.
(예: 수행-수행-메모리 읽기... 이런 식이면 2개의 수행 명령어를 동시에 처리할 수 있지만
수행-메모리 읽기-수행-메모리 쓰기-수행 이런식이면 수행 명령어의 병렬 처리가 불가능합니다)
즉 정확한 용어로 프론트엔드와 백엔드의 동작이 독립적이지 않다는 것이 문제인데요,
이러한 문제점은 1996년 출시된 AMD의 K5에서 '비순차적 수행' 구조로 해결되었습니다.
그 얼마 뒤 출시된 펜티엄 프로 CPU도 비슷한 비순차적 수행 구조를 채택하고 있습니다.
비순차적 수행에 관해서는 잠시 후 이들 CPU를 설명하면서 함께 언급하겠습니다.
펜티엄의 프론트엔드는 메모리로부터 최대 16바이트에 해당하는 길이의 명령어 스트림을 인출해 옵니다.
이 스트림에서 매 사이클당 1개의 x86 명령어가 디코더로 전송되고,
디코더는 이를 1~2개의 내부 명령어 포맷(마이크로옵: uop이라 쓰겠습니다)으로 변환합니다.
(진한 빨간색 화살표는 x86 명령어의 흐름을, 분홍색 화살표는 마이크로옵의 흐름을 나타냅니다.
또한 마이크로옵 중 진한 분홍색은 항상 생성되는 마이크로옵의 수를 의미하고
연한 분홍색은 이론적으로 생성 가능한 최대 마이크로옵 수를 의미합니다. 이하 동일)
디코드된 마이크로옵은 순차 제어 유닛으로 이동하고 제어 유닛은 마이크로옵을 백엔드에 전달하게 됩니다.
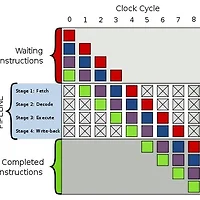
프론트엔드의 구조가 단순한 만큼, 펜티엄의 총 파이프라인 스테이지 수는 5개로 비교적 짧은 편입니다.
페치가 1스테이지, 디코드가 2~3스테이지, 제어가 4스테이지에 위치하고 마지막 단계에서 수행이 일어납니다.
2. AMD K5 Microarchitecture
AMD의 K5는 SUN으로부터 라이선스를 받은 SPARC 29000의 구조를 바탕으로 만들어졌습니다.
RISC CPU인 SPARC 29000과 달리 x86 명령어를 지원해야 하는 K5에는 디코더가 추가되어 있습니다.

K5의 디코더는 페치 버퍼로부터 사이클당 2개의 x86 명령어를 전송받아 4개의 마이크로옵으로 변환합니다.
변환된 마이크로옵은 재정렬 버퍼(ROB)에 16개까지 축적되는데, 이 ROB가 매우 중요한 역할을 수행합니다.
바로 펜티엄의 약점이었던 '순차 수행 구조'를 비순차적으로 바꿔 주는 역할이죠.
이로 인해 K5는 프론트엔드에서 일어나는 작업(인출, 디코드)과 완전히 별개로 백엔드가 작동할 수 있습니다.
명령어가 어떤 순서로 디코드되든 상관없이 백엔드는 최적의 수행 순서로 재정렬된 마이크로옵을 받는 것이죠.
백엔드의 성능 자체는 당시 이미 검증되었던 RISC 프로세서인 SPARC 29000과 동일합니다.
전반적으로 펜티엄보다 진보된 구조(밑에 설명할 펜티엄 프로에 더 가깝습니다), 높은 클럭당 성능에 불구하고
당시 AMD의 생산기술의 한계로 칩의 수율이 좋지 않아 시장에서 인기가 없었습니다.
3. Intel P6 (Pentium Pro/II/III) Microarchitecture
앞에서 살펴본 펜티엄의 문제는 프론트엔드와 백엔드의 작동이 완벽히 독립적이지 않다는 점이었습니다.
수퍼스칼라 구조로 넓어진 백엔드 대역폭을 제대로 활용하려면
마이크로옵을 재정렬해서 동시에 수행 가능한 대역폭만큼의 마이크로옵을 백엔드에 전달해줘야 하는데
펜티엄과 같은 순차 수행 구조 하에선 마이크로옵의 재정렬이 거의 불가능합니다.
AMD의 K5 및 인텔의 펜티엄 프로 CPU는 프론트엔드 말미에 재정렬 버퍼(ROB)를 넣어 이를 해결했습니다.

펜티엄 프로는 디코더 뒤에 40개의 마이크로옵을 축적할 수 있는 ROB를 가지고 있습니다.
또한 펜티엄 프로는 디코더 자체의 구조도 펜티엄에 비해 매우 향상되었습니다.
구체적으로, 명령어 인출 단계에서 페치 버퍼에 저장되는 명령어 스트림의 용량이 32바이트로 두 배 늘었고
페치 버퍼로부터 디코더로 전송되는 x86 명령어 개수가 종전의 사이클당 1개에서 사이클당 3개로 늘었습니다.
펜티엄 프로는 총 3개의 디코더를 가지는데, 단순 디코더 두 개와 복합 디코더 한 개로 구성됩니다.
단순 디코더(Simple Decoder)는 클럭당 1개의 x86 명령어를 1개의 마이크로옵으로 변환하고
복합 디코더(Complex Decoder)는 클럭당 1개의 x86 명령어를 1~4개의 마이크로옵으로 변환해 줍니다.
즉 종합하면 펜티엄 프로는 클럭당 3개의 x86 명령어를 3~6개의 마이크로옵으로 변환할 수 있습니다.
얼핏 보기엔 사이클당 6개의 마이크로옵이 생성되는데 백엔드에는 사이클당 최대 5개씩만을 전달하므로
백엔드가 CPU 성능에 발목을 잡는 것이 아닌가 의아해하실 수 있을 텐데요,
사실 P6의 디코더에는 한 가지 함정이 있습니다.

메모리 접근 관련 x86 명령어(로드/스토어)는 두 개의 마이크로옵(Address/Data)으로 디코드됩니다.
따라서 로드/스토어 명령어는 단순 디코더에서 처리할 수 없고 복합 디코더로 전송되어 처리되어야 하는데
메모리 접근이 잦은 서버/오피스 프로그램의 경우 이러한 메모리 명령어가 디코더의 대역폭을 잠식합니다.
위의 그림에서 보이는 바와 같이 메모리 명령어만 연속적으로 주어질 경우엔
3개의 디코더 중 나머지 두개는 개점휴업 상태가 됩니다. (∵메모리 명령어는 단순 디코더가 처리할수 없음)
즉 클럭당 3개의 x86 명령어 -> 6개의 마이크로옵이었던 디코드 성능이
클럭당 1개의 x86 명령어 -> 2개의 마이크로옵이 되어 거의 1/3 수준으로 급감하는 것이죠.
또한 코어 마이크로아키텍처 이전까지의 인텔 CPU의 백엔드는 FPU가 80bit 명령어만을 처리할 수 있었는데
128bit 부동소수점 벡터 명령어의 경우 80bit 대역폭을 넘지 않기 위해
64bit 명령어 두개로 쪼개야 하는 문제가 있었습니다. (즉 128bit 벡터 명령어도 복합 디코더만을 점유함)
결과적으로, P6의 디코더는 P5보다 크게 향상된 구조이기는 하나
- 메모리 접근 명령어
- 128bit 부동소수점 벡터 명령어
의 경우 디코드 성능이 크게 떨어지는 문제점이 있었습니다.
이 문제점은 Pentium III때까지 존속되다가, P6 아키텍처가 재등장한 Pentium M에서 해결됩니다.
4. AMD Chomper (K6) Microarchitecture
AMD는 펜티엄 II의 경쟁상대로 K5를 개량한 K6을 개발합니다.

K6은 K5의 구조에서 크게 달라진 점은 없으나 ICU (ROB를 부르는 다른 이름입니다.) 의 용량이
종전 16 엔트리 (16개의 마이크로옵 저장) 에서 24 엔트리로 50% 증가했습니다.
또한 백엔드 구조의 개선이 있어 클럭당 최대 6개의 마이크로옵을 병렬 수행할 수 있는 구조입니다.
하지만 같은 세대 인텔 CPU와 비교하여, K6은 FPU 파이프라인 스테이지가 분화되지 않은 약점으로 인해
당시 서서히 용도가 부각되던 FPU 성능 (멀티미디어) 이 크게 떨어져 역시 펜티엄 II와 경쟁하진 못했습니다.
하지만 뛰어난 정수 성능 (동클럭 펜티엄 II보다 빠름) 과 저렴한 가격을 바탕으로 시장의 호응을 얻었습니다.
5. AMD K7 Microarchitecture
K6의 상업적인 성공에 고무된 AMD는 NexGen을 인수하고 모토롤라와 손을 잡아 새 프로세서를 개발합니다.
(모토롤라는 Apple, IBM과 더불어 RISC CPU 개발 카르텔인 AIM Alliances 을 이끌던 회사입니다.
AMD는 인텔과 x86 CPU로 경쟁함에도 불구하고 그간 RISC CPU 제조업체와 밀접한 관계를 맺어 왔습니다.)

K7의 디코더 구조를 알아보기 전에 우선 AMD가 새로 도입한 개념들을 짚고 넘어가야 합니다.
인텔의 용어에서 '매크로옵'이란 디코드되지 않은 x86 명령어를 지칭하는 말로 마이크로옵의 반대 개념이지만
여기서 소개할 AMD의 '매크로옵'이란, 디코드된 마이크로옵 두 개를 융합한 것을 지칭합니다.
(첨언하자면, 이후 펜티엄 M에서 설명할 '퓨전 마이크로옵'의 유사 개념이기도 합니다)
K7은 세 개의 디코더를 갖고 있는데, 각각의 디코더는 두 가지 작동 모드를 가집니다.
- DirectPath (= FastPath) : 1개의 매크로옵으로 변환되는 x86 명령어를 처리
- VectorPath : 2개의 매크로옵으로 변환되는 x86 명령어를 처리
(※ 드물게 3개 이상의 매크로옵으로 변환되는 x86 명령어도 있기 때문에 이 때를 대비해 '마이크로코드 엔진'이란 장치가 있는데 이러한 명령어의 비중은 대개 코드 전체에서 차지하는 비중이 극히 미미하므로 마이크로코드 엔진에 대한 설명은 생략하도록 하겠습니다)
x86 명령어는 최소 1개의 매크로옵으로 변환되는데, 매크로옵은 사실 마이크로옵 2개의 융합체이기 때문에
애초 1개의 마이크로옵으로 변환될 수 있었을 x86 명령어 2개를 1개의 매크로옵으로 합치는 것이 가능합니다.
구체적으로, K7의 디코더는 산술 명령어 1개와 메모리 접근 명령어 1개를 매크로옵으로 묶을 수 있습니다.
다만 인접한 산술+메모리 접근 명령어 조합이 없을 때에는 마이크로옵 1개만으로 매크로옵을 생성합니다.
즉 이 경우에는 산술 명령어+NoOp, 또는 NoOp+메모리 접근 명령어 조합이 되는 것이죠.
매크로옵 구조의 좋은 점은 여러 x86 명령어를 디코드한 뒤 추적하는 데 드는 자원이 절감된다는 점입니다.
즉 종합하면 K7의 디코더는 클럭당 3개의 x86 명령어를 전송받아 3~6개의 매크로옵을 생성합니다.
이는 인텔 P6의 디코더의 약점 가운데 하나였던 메모리 관련 명령어의 대역폭 잠식이 해결된 구조입니다.
또한 명령어 제어 유닛 (ICU) 의 용량이 종전 K6의 세 배인 72 엔트리로 크게 늘었습니다.
당시 경쟁 제품이었던 인텔 펜티엄 III(40 엔트리)보다도 80%나 더 넓은 ROB를 가진 셈입니다.
6. Intel Netburst Microarchitecture
펜티엄 III 시기에 인텔은 가장 큰 라이벌로 부상한 AMD의 애슬론에 고전하게 됩니다.
펜티엄 III보다 뛰어난 성능과 더 높은 클럭까지 도달 가능했던 애슬론의 마케팅적 요소를 본받아
인텔은 클럭을 높이는 데 올인하여 펜티엄 4의 근간이 되는 넷버스트 아키텍처를 설계합니다.
넷버스트 아키텍처는 클럭을 높이기 위해 깊은 파이프라인 설계에 올인하여 다른 많은 요소를 희생했습니다.
파이프라인 스테이지는 프로세서가 1클럭당 수행하는 작업의 묶음인데,
파이프라인 스테이지를 잘개 쪼갤수록 1클럭당 수행하는 작업이 줄어들기 때문에 클럭을 높이기는 쉽지만
그만큼 하나의 연산을 완료하기 위해 걸리는 클럭 사이클이 많아지므로 IPC는 크게 떨어지는 설계입니다.

넷버스트 아키텍처는 집적할 수 있는 트랜지스터의 많은 양을 깊은 파이프라인 구현에 투입하였고
결과적으로 당대의 어떤 CPU보다도 간소한 백엔드와 프론트엔드 구조를 가질 수밖에 없었습니다.
당장 전세대의 P6 아키텍처만 해도 백엔드가 동시에 처리할 수 있는 마이크로옵 갯수가 5개였는데 비해
넷버스트 아키텍처는 최대 4개의 마이크로옵밖에 처리할 수 없는 구조입니다.
또한, 프론트엔드 디코더의 설계도 크게 퇴보하여 오리지널 펜티엄과 동급의 디코딩 성능을 갖게 되었습니다.
넷버스트의 디코더는 클럭당 1개의 x86 명령어를 전송받아 1~4개의 마이크로옵으로 변환합니다.
산술적으로, 펜티엄 III에 비해 매 클럭당 디코드 가능한 x86 명령어 갯수가 1/3로 줄어든 것입니다.
이런 열악한 디코드 성능을 만회하기 위해 넷버스트 아키텍처에서는 디코더 뒤에 캐시가 위치합니다.
보통의 L1-Instruction 캐시에 해당하는 트레이스 캐시가 바로 그것입니다.
일반적으로 캐시는 프론트엔드 이전 단계에 위치해서,
CPU가 메모리로부터 명령어를 인출하는 시간을 줄이는 역할을 수행하지만 트레이스 캐시는 조금 다릅니다.
디코더 뒤에 위치하여 디코드 된 마이크로옵을 저장함으로써 디코딩 과정을 생략하게끔 도와주는 것이죠.
즉 트레이스 캐시에 저장된 명령어를 가져 오는 경우
기존 CPU들은 L1캐시 -> 페치 -> 디코드 -> ROB -> 백엔드의 5단계를 거쳐야 했지만
넷버스트는 트레이스 캐시 -> ROB -> 백엔드의 3단계만 거치면 됩니다.
하지만 필연적으로 언젠가는 캐시 미스 (Cache miss) 가 발생하기 마련이고
이런 경우엔 넷버스트의 느린 디코더가 명령어를 디코드하기를 기다려야 하므로 큰 성능 저하가 발생합니다.
(특히 다른 아키텍처보다도 넷버스트는 깊은 파이프라인 때문에 '기다림' 이 성능에 치명적인 구조입니다)
넷버스트 아키텍처의 트레이스 캐시는 12,000개의 마이크로옵을 저장해둘 수 있습니다.
기존의 L1 캐시로 환산하면 대략 16~18KB에 해당하는 용량이 됩니다.
그 밖에, 넷버스트 아키텍처에서는 ROB가 P6에 비해 크게 늘어 최대 126개의 명령어를 축적해 둘 수 있어
보다 효율적인 재정렬 및 병렬 전송이 가능합니다. 좁아진 백엔드 대역폭을 최대한 활용하기 위한 방편입니다.
7. AMD K8 / K10 / K10.5 Microarchitecture
K7로 경쟁사의 기를 꺾는 데 성공한 AMD는 K8 아키텍처를 설계하며 보다 근본적인 변화를 도모합니다.
바로 8086 시절부터 20년 넘게 사용해 온 x86 ISA (명령어 세트 아키텍처) 를 자사 주도로 바꿔 낸 것이죠.
사실 오래된 x86 ISA를 바꾸려는 시도는 이 ISA의 창시자 격인 인텔에서 먼저 있었습니다.
하지만 IA-64라 이름붙여진 새 ISA를 적용한 'Itanium' CPU가 시장에서 별 반응을 얻지 못하고 표류하던 찰나
AMD는 2003년 경 자사 주도의 새로운 ISA인 'x86-64' ISA를 제안하고, 이를 적용한 CPU인 K8을 발표합니다.
K8은 기존 x86 ISA에 대한 호환성과, 무엇보다 뛰어난 성능을 바탕으로 시장에서 즉시 채택되게 됩니다.
K8은 하드웨어적인 측면만 보자면 K7을 소폭 개량한 버전입니다.

페치 버퍼의 용량이 두 배로 커진 것이 유일한 가시적인 변화입니다.
(사실 디코더 뒤에 팩/디코드라는 단계가 추가되었지만 여기에서는 언급하지 않겠습니다)
K8의 디코더에서 개선된 부분은 매크로옵으로 융합할 수 있는 마이크로옵의 종류가 늘어났다는 것으로
기존의 산술+메모리 조합 외에도 64bit 마이크로옵 두개로 변환되는 128bit 벡터 명령어가 추가되었습니다.
종전에는 128bit SSE 명령어가 들어오면 두 사이클에 걸쳐 64bit 마이크로옵으로 디코드해야 했지만
K8에서는 한 사이클만에 하나의 128bit SSE 명령어를 한 개의 매크로옵으로 변환할 수 있게 된 것입니다.
(이는 인텔 코어 듀오/솔로가 펜티엄 M으로부터 개선된 점과 동일합니다.)
한편, K10 아키텍처는 하드웨어 구조적으로는 K8과 완전히 동일하고,
백엔드 FPU의 대역폭이 80bit에서 128bit로 향상되어 128bit 벡터 연산을 한 사이클만에 완료할 수 있습니다.
8. Intel P6 (Pentium M) Microarchitecture
넷버스트 아키텍처는 낮은 클럭당 성능으로 인한 혹평에도 불구하고
설계 당시 의도한 바와 같이 높아진 클럭으로 인해 마케팅상 유리한 고지에 설 수 있었습니다.
하지만 엉뚱한 곳에서 문제가 발생했는데, 불완전한 90nm 공정으로의 이전이 문제였습니다.
90nm 공정으로 제조된 첫 CPU인 프레스캇은 무려 31단계로 깊어진 파이프라인 스테이지을 갖고 있었는데
높은 소비전력과 발열로 인해, 깊은 파이프라인으로 희생된 IPC를 상쇄할 만큼 클럭이 올라가지 못했습니다.
따라서 인텔은 넷버스트 아키텍처를 폐기하고 기존의 P6 아키텍처를 되살려 새로운 CPU를 설계합니다.
모바일로 처음 데뷔한 펜티엄 M이 바로 그것입니다.

펜티엄 M은 기존 P6과 거의 똑같은 백엔드 구조를 가졌고 프론트엔드 구조가 약간 변화되었습니다.
페치 버퍼와 ROB의 용량이 각각 P6보다 두배 늘었고, 디코더에 '마이크로옵 퓨전'이란 기능이 추가되었는데
바로 이것이 기존 P6 아키텍처에서 문제가 되었던 로드/스토어 명령어의 성능저하를 해결해주는 방편입니다.
기존에는 복합 디코더에서만 처리 가능한 메모리 접근 명령어가 연속적으로 전달될 경우
다른 두 개의 단순 디코더가 유휴상태가 되어 디코더 대역폭이 1/3 수준으로 줄어드는 문제가 있었는데
펜티엄 M에서는 이들 또한 단순 디코더로 전달되어 한 개의 '퓨전 마이크로옵'으로 변환됩니다.
퓨전 마이크로옵의 개념은 AMD의 '매크로옵'과 매우 비슷합니다.

기본적으로 퓨전 마이크로옵은 기존의 마이크로옵을 두개 합친 것과 같습니다.
메모리 접근 명령어의 경우 재정렬의 효율이 크지 않고, 하나처럼 붙어 다녀도 성능상 큰 영향이 없으므로
디코더 -> ROB -> 백엔드에 이르기까지 따로 분해하지 않고 묶어 두는 것이죠.
이러한 설계로 인해 펜티엄 M은
- 디코딩 성능의 향상
- 디코더 유휴상태의 방지. 즉 하는 일 없이 전기를 소모하는 경우를 없앰
라는 두가지 토끼를 잡을 수 있었습니다.
이후 등장한 코어 듀오/솔로 프로세서에서는 128bit 벡터 명령어의 마이크로옵 퓨전도 지원되기 시작했습니다.
즉 애초 P6 아키텍처의 디코더의 약점으로 지적되었던 부분들을 모두 개선한 것이죠.
9. Intel Core Microarchitecture
인텔은 펜티엄 M의 개량된 P6 아키텍처를 더욱 발전시켜 '코어' 아키텍처를 쓴 코어2 CPU를 발표합니다.
코어2의 백엔드는 역대 최고속이었던 AMD 애슬론의 백엔드와 같은 대역폭(6-uop 병렬 처리)을 지원하며
이에 걸맞게 코어 아키텍처에서는 프론트엔드에도 큰 변화가 있었습니다.

일단 페치 버퍼와 디코더 사이에 '루프 탐지기'라는 하드웨어가 추가되었습니다.
코어2의 루프 탐지기는 18개의 x86 명령어를 저장할 수 있는 일종의 버퍼인데,
프로그램에서 루프가 탐지될 경우 (즉 몇 개의 명령어를 반복적으로 수행할 경우)
분기 예측 및 페치 과정을 생략하고, 자신이 저장한 명령어를 곧바로 디코더에 전달해 줍니다.
루프 탐지기의 등장으로 상대적으로 페치 버퍼의 중요성이 줄어
코어의 페치 버퍼 용량은 펜티엄 M의 절반 수준으로 줄어들었습니다.
한편 코어2의 디코더는 종전 P6의 3개에서 4개로 증가된 형태입니다. (단순 디코더가 1개 증가)
거기다가 디코드 전 단계에 '매크로옵 퓨전'이란 기능이 추가되었는데, x86 명령어 두 개를 하나로 묶은
'퓨전 매크로옵'을 사이클당 한 개씩 생성해 네 개의 디코더 중 하나로 전송할 수 있습니다.
즉 사이클당 디코더로 전송 가능한 x86 명령어의 갯수는 총 4+1 = 5개가 되는 셈이죠.
기존 P6 프론트엔드의 사이클당 3개 x86 명령어에서 67%나 증가한 수치입니다.
(※ AMD의 매크로옵이란 용어와 혼동을 방지하기 위해 그림에는 x86-op Fusion으로 표시했습니다.
AMD의 매크로옵과 코어2의 매크로옵이란 용어는 개념이 약간 다른데,
AMD의 매크로옵은 이미 디코드된 마이크로옵 두개를 융합한 것이고
코어2의 매크로옵은 디코드되지 않은 x86 명령어 두개를 융합한 것입니다)
매크로옵 퓨전이 가능한 명령어의 종류는 한정적인데, 코어2는 다음의 두 가지를 묶을 수 있습니다.
- Compare-and-test 명령어
- 분기 명령어
또한 기존의 CPU들은 백엔드의 FPU가 받을 수 있는 명령어 대역폭이 80bit로 한정되어 있었는데
코어2는 FPU 대역폭을 128bit로 확장해서, 128bit 벡터 명령어를 한 사이클만에 처리할 수 있습니다.
이 덕분에 코어2는 부동소수점 벡터 성능이 거의 두 배에 가깝게 향상될 수 있었습니다.
종합하면, 코어2는 사이클당 최대 5개의 x86 명령어를 7개의 (퓨전)마이크로옵으로 변환할 수 있는데
기존의 x86 명령어:마이크로옵 비율과 비교하면 상대적으로 더 1:1에 가까워진 것을 알 수 있습니다.
- P5: 1개의 x86 -> 2개의 마이크로옵 (1:2 = 200%)
- P6: 최대 3개의 x86 -> 6개의 마이크로옵 (1:2 = 200%)
- 넷버스트: 1개의 x86 -> 4개의 마이크로옵 (1:4 = 400%)
- 코어: 5개의 x86 -> 7개의 마이크로옵 (5:7 = 140%)
이것이 의미하는 것은 x86 명령어당 마이크로옵 비율이 줄어듦에 따라,
쓸데없이 많이 생성된 마이크로옵을 추적하는 데 드는 자원(= 소비전력)을 줄일 수 있다는 점입니다.
10. Intel Nehalem Microarchitecture
코어2 시리즈의 인상적인 성능을 발판으로 인텔은 이를 소폭 개량한 네할렘 아키텍처를 발표했습니다.

네할렘의 백엔드는 코어의 백엔드와 똑같고, 프론트엔드 구조도 아래의 4가지를 제외하면 거의 비슷합니다.
- 페치 버퍼의 크기
- 루프 탐지기의 위치
- 루프 탐지기의 용량
- ROB의 용량
일단, 네할렘에서는 루프 탐지기를 종전의 페치 버퍼~디코더 사이에서 디코더~ROB 사이로 옮겼습니다.
따라서 루프가 감지될 경우 기존의 분기예측/인출 뿐만 아니라 디코딩 과정까지 생략할 수 있게 되었는데
보기에 따라서 넷버스트 아키텍처의 트레이스 캐시와 유사한 구조라고 생각할 수 있습니다.
또한 기존에는 루프 탐지기가 18개의 x86 명령어를 저장할 수 있었는데
네할렘 아키텍처에서는 28개의 마이크로옵을 저장하도록 바뀌었습니다.
x86 명령어와 마이크로옵을 일대일로 비교할 수는 없지만 대략 1.5배 가량 늘어난 용량입니다.
향상된 루프 탐지기로 인해 상대적으로 페치 버퍼의 역할이 줄어들었기 때문에
페치 버퍼의 용량은 크게 줄어들었습니다. 코어/넷버스트/P6보다 작은 것은 물론 P5와 비슷한 수준입니다.
또한 네할렘 아키텍처에서는 매크로옵 퓨전 될 수 있는 x86 명령어의 종류가 몇가지 더 추가되었습니다.
한편 ROB의 용량도 종전 코어의 96 엔트리에서 128 엔트리로 33.3% 증가했는데,
덕분에 더 효율적인 재정렬 및 백엔드로의 명령어 동시 공급이 가능해졌습니다.
대체로 스루풋은 ROB 용량에 비례하므로 네할렘은 코어보다 최대 33.3% 향상된 IPC를 갖게 되었습니다.
11. Intel Sandy Bridge Microarchitecture

샌디 브릿지의 디코더 구조는 네할렘 아키텍처와 거의 같습니다.
샌디 브릿지의 주된 변화점은 과거 넷버스트에서 쓰였던 '트레이스 캐시' 를 공식적으로 재도입했다는 것과
ROB의 용량이 네할렘의 128 엔트리에서 168 엔트리로 31% 가량 향상되었단 것입니다.
과거 넷버스트 아키텍처에서 트레이스 캐시가 L1-Instruction 캐시를 대체한 것과 달리
샌디 브릿지는 그대로 L1-Instruction 캐시를 가지면서 프론트엔드에 트레이스 캐시가 추가된 형태입니다.
그 밖에도 샌디 브릿지는 백엔드 부동소수점 포트의 대역폭을 256bit로 확장해
256bit AVX 명령어를 한 사이클에 처리할 수 있게 되어 향후 성능향상이 기대되고 있습니다.
(다만 기존의 128bit 명령어를 두배 빨리 처리한다든지 하는 식의 응용은 불가능해
대역폭 확장으로 인한 기존 어플리케이션에서의 성능 향상은 거의 없다는 한계를 가집니다)
12. AMD Bulldozer Microarchitecture
불도저는 전통적인 AMD의 디코더 구조를 바탕으로 인텔이 도입한 여러 기법들을 채용했습니다.
프론트엔드 구조를 설명하기에 앞서, 우선 불도저의 '모듈'구조를 짚고 넘어가도록 하겠습니다.
아시다시피 1 불도저 모듈은 명목상 2코어로 작동하지만 실제 2코어로 보기엔 불완전한 부분이 많습니다.
백엔드 레벨에서 '두 코어'가 부동소수점 유닛을 공유한다는 점 외에도 근본적으로 2코어가 아닌 이유는
프론트엔드 레벨에서 대부분의 단계를 '두 코어'가 공유하고 있기 때문입니다.
즉 CPU 성능을 핵심적으로 좌우하는 디코더 및 ROB는 1모듈당 한 세트밖에 탑재되어 있지 않습니다.
즉 불도저가 '2코어'에 걸맞게 보유하고 있는 하드웨어는 사실 백엔드의 정수/메모리 유닛밖에 없어
단지 이것만을 근거 삼아 1 불도저 모듈을 2코어로 정의하기엔 어려움이 있습니다.
그럼 이제 불도저의 프론트엔드 구조를 보도록 하겠습니다.

큰 틀에서 디코더 구조는 기존의 AMD 방식을 따르고 있습니다.
하나의 디코더가 내부적으로 Direct Path / Vector Path 두 가지의 작동 모드를 가지며,
1개의 매크로옵으로 변환될 x86 명령어는 Direct Path에 배정돼 사이클당 1개의 매크로옵을 생성하고
2개의 매크로옵으로 변환될 x86 명령어는 Vector Path에 배정돼 사이클당 1개의 매크로옵이 됩니다.
'매크로옵'으로 묶일 조건은 1개의 산술 명령어와 1개의 메모리 접근 명령어가 쌍을 이루는 것인데
서로 인접한 산술/메모리 접근 명령어가 없을 때에는 각자 NoOp을 포함한 1개의 매크로옵이 됩니다.
즉 정수 연산/Load Address 명령어가 인접해 있을 때는 이 둘이 하나의 매크로옵으로 융합되지만
산술 명령어만 연속적으로 들어오는 경우라면 각 산술 명령어는 "산술-NoOp" 형태의 매크로옵이 됩니다.
즉 디코더의 대역폭을 최대한 활용하기 위해서는 들어오는 명령어의 조합이 대단히 중요합니다.
불도저는 이러한 디코더를 4개 내장해 사이클당 4개씩의 x86 명령어를 매크로옵으로 변환하며,
생성되는 매크로옵 갯수는 사이클당 4개~8개가 됩니다. (마이크로옵 단위로는 최저 4개~최대 16개)
이렇게 생성된 매크로옵은 ICU(ROB에 해당)에 저장되는데, ICU의 용량이 종전 K10의 72-Entry에 비해
128-Entry로 거의 78%가량 늘어 불도저의 스루풋 역시 그만큼 향상되었을 것으로 짐작됩니다.
ICU는 백엔드와 연결되어 각 정수 코어 및 공유 부동소수점 유닛에 각각 4개씩의 매크로옵을 전송합니다.
즉 총 명령어 포트가 12개인 셈으로 불도저는 지금까지 발표된 어떤 CPU보다도 넓은 백엔드를 가집니다.
주목할 점은 인텔 CPU에 도입되었던 루프 탐지기(Loop Stream Detector)와 트레이스 캐시의 등장입니다.
루프 탐지기는 앞서 인텔 코어 아키텍처에 대해 설명하면서 언급한 바 있는데,
명령어의 루프가 감지될 경우 해당 루프 전체를 탐지기 내부에 저장해서
루프가 종료될 때까지 별도의 인출 절차를 생략하고 바로 탐지기로부터 명령어를 공급받도록 합니다.
이 장치는 코어 아키텍처가 전세대에 비해 압도적인 성능 향상을 이룰 수 있던 비결 중 하나입니다.
또한 트레이스 캐시는 인텔 넷버스트 아키텍처 및 최근의 샌디 브릿지에서 도입된 장치로
디코드되기 전 단계의 x86 명령어를 저장해두는 기존의 L1-Instruction 캐시와 달리 이미 디코드된 마이크로옵을 저장해 둠으로써 캐시를 억세스할 때 인출-디코드 절차를 생략할 수 있습니다.
트레이스 캐시가 완전히 L1-Instruction 캐시를 대체했던 넷버스트와는 달리 불도저는 샌디 브릿지처럼 L1-Instruction 캐시와 트레이스 캐시가 CPU 내부에 공존하는 형태인데 이 덕분에 트레이스 캐시는 일종의 "L0 캐시" 처럼 기능하게 됩니다.
불도저의 트레이스 캐시 및 (그림에는 표시되지 않았지만) L1-Instruction 캐시는 각 코어별로 분화되어 각각 별개의 스레드를 전담하는 역할을 합니다. (이와 달리 L1-Data 캐시는 두 코어가 공유합니다)
아시다시피 불도저는 기본적으로 1모듈-2스레드 구조인데, 불도저의 싱글스레드 성능도 궁금하실 겁니다.
싱글스레드만을 지원하는 어플리케이션 하에서 가동되는 불도저의 프론트엔드 유닛은 아래와 같습니다.

이로써, 크리티컬 패스의 위치에 따라 다르겠지만, '싱글코어' 불도저의 성능은 대략 아래와 같을 것입니다.
- 디코더가 병목현상을 유발할 경우: K10 대비 33% 향상
- 병목현상이 없을 경우: (ROB의 In-flight 명령어 갯수에 비례해) K10 대비 78% 향상
- 백엔드가 병목현상을 유발할 경우: K10 대비 33% 향상
즉 불도저의 싱글스레드 성능은 전세대에 비해 매우 큰 폭으로 향상될 것이 확실시됩니다.
오히려 상당수의 유닛을 공유하기 때문에 멀티스레드 성능이 기존만큼 크게 증가하지 않을 가능성이 있는데
기존의 '느린 코어를 많이 집어넣는' K10까지의 전략과는 분명히 다른 방향이라고 할 수 있습니다.
//
아래 위젯은 일종의 크라우드펀딩 플랫폼인 티스토리 '밀어주기' 서비스 위젯입니다. 100원부터 3000원까지의 범위 내에서 소액기부가 가능하며, 이런 형태의 펀딩이 성공적일 경우 '이해관계자로부터 독립된 벤치마크' 의 지속 가능한 원동력이 되리라 생각합니다. 물론 후원 없이 제 글을 읽어 주시는 것만으로도 저는 독자 여러분께 감사합니다 :)
'Lecture & Column > cpu_lec_col' 카테고리의 다른 글
| 파이프라이닝의 이해 (22) | 2011.03.02 |
|---|---|
| 멀티스레딩 기술의 이해 (53) | 2011.02.05 |
| 현대 CPU의 구조 : 백엔드 편 (54) | 2011.01.22 |
| 오버클럭의 공학적 배경 (26) | 2011.01.14 |
| 현대 CPU의 구조 : 메모리 계층 구조와 성능 (9) | 2010.11.24 |