Author : Daeguen Lee
(Any action violating either copyright laws or CCL policy of the original source is strictly prohibited)
오늘날 컴퓨터는 다양한 형태와 기능을 갖추고 인간의 생활을 도와주고 있습니다.
재미있는 점은 컴퓨터들이 쓰이는 용도나 형태가 천차만별임에도 그 기본 원리는 거의 같다는 점입니다.
공학용 계산기나 비행기의 자동항법장치나 그 복잡도에 차이가 있을 뿐 큰 틀에서 작동하는 원리는 같습니다.
"데이터/명령어를 읽고, 읽은 것을 수행하고, 결과를 쓴다."
이 간단한 작동을 위해 최소한으로 필요한 요소는 다음의 세 가지입니다.
- 저장 장치
- ALU (Arithmetic and Logic Unit, 산술 논리 유닛)
- 버스 (데이터/명령어가 저장 장치와 ALU 사이를 오가는 통로입니다)
저장 장치에 있는 데이터와 명령어를 버스를 통해 읽어 와서 ALU가 연산을 수행하는 것.
이 간단하고 추상적인 원리가 복잡한 컴퓨터의 시발점입니다.
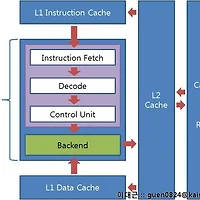
실제 컴퓨터의 구조를 그림으로 나타내 보겠습니다.

위에서 설명한 모델을 조금 확장한 그림입니다.
빨간 화살표는 버스,
CPU라고 묶인 부분은 ALU,
L1/L2/L3 캐시 및 RAM은 저장 장치를 의미합니다.
위에서 CPU라고 표시한 부분은 크게 프론트엔드와 백엔드라는 두 부분으로 구분됩니다.
CPU가 읽은 명령어를 연산장치가 해석할 수 있는 더 간단한 코드로 전환해주는 부분을 프론트엔드라 하고
프론트엔드가 해석해 준 코드와 데이터를 받아 실제로 연산을 수행하는 부분을 백엔드라고 합니다.

실제로 연산을 수행하는 것이 백엔드이기 때문에 CPU의 성능은 곧 백엔드의 성능일 꺼라 생각하기 쉽지만,
사실 CPU가 읽어들인 명령어가 가장 많이 시간을 보내는 곳은 프론트엔드의 '디코드' 단계입니다.
프론트엔드는 명령어 인출, 디코드, 제어(백엔드로 디코드된 명령어 코드를 이송)의 세 부분으로 나뉩니다.
한편, 주로 저장 장치로 쓰이는 RAM의 속도는 CPU의 속도에 비해 많이 떨어지므로
CPU가 메모리에서 데이터/명령어를 기다리며 시간을 허비하지 않기 위해 보다 빠른 메모리를 사이에 둡니다.
이것을 캐시(Cache)라고 하고, 캐시의 속도와 위치에 따라 다시 위계질서가 생겨납니다.
CPU에 가장 가까운 캐시를 레벨 1(L1) 캐시라고 하고, 보통 L1 캐시는 명령어/데이터로 역할을 분담합니다.
이 글에서는 백엔드의 구조를 중심으로, 1994년 펜티엄부터 2011년 불도저까지의 CPU를 분석하고자 합니다.
1. Intel P5 (Pentium) Microarchitecture

1994년에 출시된 인텔 펜티엄 CPU의 백엔드입니다. (녹색 상자 안의 부분)
(백엔드의 하얀 상자는 수행 유닛 (Execution Unit) 을 나타냅니다. 이하 동일)
프론트엔드를 거친 명령어는 제어 유닛에 의해 "순차적으로" 알맞은 수행 유닛으로 옮겨집니다.
펜티엄 CPU는 세 개의 수행 유닛(두 개의 정수 ALU와 한 개의 FPU)을 가집니다.
80486 CPU부터 부동소수점 ALU(= FPU)를 CPU에 내장하는 것은 보편적인 일이 되었지만
하나의 CPU가 두 개의 정수 ALU를 내장한 것은 x86 데스크탑 프로세서로써는 펜티엄이 처음이었습니다.
뿐만 아니라 수행 유닛 파이프라인이 병렬 배치되어 최대 두 개의 명령어를 동시에 처리할 수 있게 되었는데
이를 수퍼스칼라 (Super Scalar: 수행 유닛 파이프라인이 여러 개) 구조라고 합니다.
이 구조는 펜티엄이 당시 워크스테이션 등에서 쓰이던 RISC CPU와 견줄 만한 성능을 갖추는데 일조합니다.
※ 파이프라인 갯수는 간단히 말해 매 사이클당 명령어를 투입할 수 있는 수행 유닛의 갯수를 의미합니다.
뒤에서 설명할 '파이프라인 스테이지' 또는 '파이프라인 깊이'와는 다른 개념임을 유념하시기 바랍니다.
파이프라인 스테이지란 각 파이프라인을 구성하는 수행 단계를 의미하고, 총 스테이지의 수를 '깊이'라 합니다.
스테이지가 짧을수록, 해당 스테이지에서 일어나는 수행이 단순함을 의미하므로 클럭 속도를 올리기 쉽지만
그만큼 한 작업을 마치기 위해서 거쳐야 하는 스테이지의 수가 늘어나는 단점이 있습니다.
펜티엄의 정수 ALU는 다시 단순 정수 유닛(S-IU)과 복합 정수 유닛(C-IU)으로 나뉩니다.
S-IU는 보통 하나의 파이프라인 스테이지에서 끝낼 수 있는 덧셈/뺄셈 연산을 수행하고
C-IU는 하나 이상의 스테이지를 차지하는 곱셈/나눗셈 연산을 수행합니다.
또한 FPU와 포트를 공유하지 않는 S-IU는 메모리 접근 유닛의 기능을 겸해 주소 계산 등을 담당합니다.
하지만 펜티엄도 구조적인 약점이 있었는데, 백엔드에 동시에 두 개의 명령어를 이슈할 수 있는 구조임에도
"순차적 수행"의 특성상 명령어 스트림을 대역폭에 맞춰 유연하게 제어하기 어렵다는 점입니다.
(이론적으로 정수 명령어 두개 또는 정수/부동소수점 명령어 각 한개를 동시에 이슈 가능합니다)
예를 들어 명령어 스트림이 정수 연산-정수 연산-부동소수점 연산의 순서로 입력된다면 좋겠지만
정수 연산-메모리 접근-부동소수점 연산-메모리 접근... 의 순서인 경우가 현실에선 더 많기 때문이죠.
이 문제는 펜티엄보다 1년 뒤에 출시된 AMD의 K5 CPU와 인텔의 펜티엄 프로 CPU에서 해결됩니다.
2. AMD K5 Microarchitecture

(백엔드의 빨간 화살표는 산술 명령어, 주황색 화살표는 메모리 접근 명령어입니다. 이하 동일)
AMD는 K5 이전까지 인텔 호환 CPU를 만들던 중소 제조업체였습니다.
1996년 K5를 시작으로 AMD는 자사만의 독자적인 구조와 노선을 걷기 시작합니다.
RISC CPU인 SPARC에 단지 CISC 명령어 디코더만을 추가한 형태인 K5는 인텔 펜티엄의 경쟁자였지만
구조적으로는 오히려 펜티엄 프로에 더 가까운 특징을 가지고 있습니다.
바로 명령어의 "비순차적 수행"을 가능하게 하는 재정렬 버퍼(Reorder Buffer: ROB)가 추가된 것입니다.
명령어 페치 -> 디코드까지는 펜티엄과 같지만, 재정렬 버퍼는 디코드된 명령어의 순서를 뒤바꿀 수 있습니다.
따라서 백엔드에 이슈할 수 있는 최대 대역폭에 맞춰 명령어를 보내줄 수 있게 된 것이죠.
(수행 -> 쓰기, 수행 -> 쓰기, ... 이런 순서를 수행/수행/수행/수행 -> 쓰기/쓰기... 이런 식으로 말입니다)
이에 대응하여 K5의 백엔드에는 예약소(Reservation Station: RS)라는 저장공간이 존재합니다.
First-In-First-Out 방식의 큐(Queue)인 RS에 축적된 명령어는 적당한 때에 각 유닛에 보내집니다.
또한 K5는 수행 유닛과 메모리 접근 유닛을 분리하여, 명령어 수행/메모리에 쓰기를 동시에 할 수 있습니다.
다만 K5는 설계 자체의 진보적인 장점과 펜티엄을 능가하던 동 클럭 성능에 불구, 칩의 수율 문제로 인하여
펜티엄을 압도할 만한 작동속도에 도달하지 못해 시장에서 큰 인기를 끌지는 못했습니다.
3. Intel P6 (Pentium Pro) Microarchitecture

AMD의 K5에 이어 인텔은 1996년에 출시한 펜티엄 프로에 비순차적 수행을 도입하는 한편
RS가 백엔드에 동시에 이슈할(보낼) 수 있는 명령어의 최대 개수를 5개로 늘리게 됩니다.
또한 펜티엄 프로는 펜티엄에 비해 프론트엔드의 파이프라인 스테이지를 크게 늘렸는데,
일반적으로 파이프라인이 늘어나면 클럭을 높이는 데 유리하지만 클럭당 성능은 떨어지는 경향이 있습니다.
따라서 진보된 설계에도 불구하고 펜티엄 프로는 동 클럭의 펜티엄보다 그리 빠르지 않았고,
당시의 제조공정상 길어진 파이프라인에도 불구하고 클럭이 그리 크게 높아지지도 않았기 때문에
일반 소비자들에게 펜티엄 프로는 펜티엄에 비해 큰 인기가 없었습니다.
(펜티엄의 파이프라인 스테이지는 5단계, 펜티엄 프로는 12단계입니다.)
하지만 펜티엄 프로의 P6 아키텍처는 1~2년 뒤 제조공정의 발달과 함께 다시 빛을 보게 됩니다.
4. AMD Chomper (K6) Microarchitecture

AMD는 1997년 인텔의 펜티엄 프로 / 펜티엄 II에 대응하여 K5를 확장한 K6을 출시합니다.
K6은 기본적으로 K5와 비슷한 구조이지만, RS가 동시에 이슈하는 명령어 수를 6개로 늘렸습니다.
또한 K6-2 부터는 최초의 부동소수점 벡터 연산유닛인 3D Now!를 탑재하여 인텔과 차별화를 꾀했습니다.
(이미 정수 벡터 유닛으로 인텔의 MMX가 있었지만, 부동소수점 벡터 유닛은 3D Now!가 처음이었습니다)
하지만 이 시기 AMD는 뛰어난 정수 성능에 비해 뒤떨어지는 부동소수점 성능으로 소비자의 외면을 받았는데,
파이프라인이 구현되지 않은 FPU의 실행 효율이 매우 낮았던 점이 원인입니다.
(인텔의 FPU는 2~4 단계의 파이프라인 스테이지를 가짐으로써 명령어 실행 효율을 높였습니다.)
하지만 전체적으로는 펜티엄 II에 준하는 성능에, 정수 성능은 오히려 펜티엄 II / III보다 뛰어났기 때문에
인텔 호환 제조사로서는 처음으로 '쓸 만한 CPU를 만드는 회사' 라는 이미지를 얻었고
K6 시리즈는 비인텔 CPU로서는 가장 뛰어난 판매고를 올리게 됩니다.
K6-III는 K6-2와 동일한 백엔드를 가지며, CPU 다이에 L2캐시를 탑재하여 레이턴시를 크게 줄였습니다.
5. Intel P6 (Pentium II / III) Microarchitecture

출시 당시 제조공정의 한계로 인기를 끌지 못했던 펜티엄 프로는, 제조공정이 발전하며 빛을 보게 됩니다.
펜티엄 II / III의 백엔드는 기본적으로 펜티엄 프로의 백엔드와 동일합니다.
펜티엄 II / III에서는 기존의 스칼라 ALU를 확장하여 SIMD 방식의 벡터 ALU를 도입했습니다.
위의 그림에서 MMX와 펜티엄 III에 도입된 SSE가 각각 벡터 ALU에 해당합니다.
이 중 MMX 유닛은 벡터 정수연산을 담당하고, SSE 유닛은 벡터 부동소수점 연산을 담당합니다.
(MMX: MultiMedia eXtentions / SSE: Streaming SIMD Extentions)
벡터연산은 다량의 데이터에 대해 비슷한 연산을 반복하는 멀티미디어 성능에 대단히 중요합니다.
또한 제조공정이 개선됨에 따라, 출시 당시 작동속도가 200MHz 전후였던 펜티엄 프로에 비해
펜티엄 II는 450MHz까지, 펜티엄 III는 1.4GHz까지 올라 많은 인기를 끌었습니다.
6. AMD K7 / K8 Microarchitecture

K6 시리즈의 상업적인 성공에 고무된 AMD는 이듬해 모토롤라와 손잡고 K7의 개발을 시작합니다.
또한 비슷한 시기 Nx686 이라는 CPU를 만들던 NexGen을 인수하며 R&D에 아낌없는 투자를 하게 됩니다.
중소 제조업체로써는 모험에 가까운 독자 개발 아키텍처로 개발된 K7은 98년 연말부터 베일을 벗어 나갔고
마침내 99년 6월 출시된 K7 '애슬론'은 당대 최고의 인텔 CPU였던 펜티엄 III를 모든 벤치마크에서 앞질렀고
2년 뒤인 2001년에는 인텔보다 이틀 먼저 1GHz CPU를 발표하며 경쟁사의 자존심을 완전히 꺾어 버렸습니다.
전작에 비해 애슬론의 성능이 비약적으로 향상된 데에는 향상된 버스 구조와 프론트엔드의 개선도 있었지만
많은 트랜지스터를 투입해 수행 유닛의 수를 크게 늘린 것이 성능 향상의 주된 원인입니다.
기존의 파이프라인되지 않은 한 개의 FPU를 파이프라인된 3개의 FPU로 바꿔 부동소수점 성능을 높였고
IU도 기존의 2개에서 3개로 늘려 정수 성능을 이론적으로 50% 가까이 끌어올릴 수 있었습니다.
또한 정수 명령어와 메모리 접근 명령어가 보통 쌍을 이루는 점에 주목해 그 둘을 묶은 '매크로옵' 개념을 도입,
RS에서 명목상 6개의 명령어(매크로옵)을 이슈하지만 실질적으로 최대 9이슈의 효과를 볼 수 있었습니다.
또한 RS와 수행유닛 사이에 스케줄러란 별도의 큐를 도입해 넓은 백엔드 대역폭을 효율적으로 쓰게 했습니다.
애슬론은 출시 당시 현존하던 펜티엄 III의 최고 속도이던 600MHz보다 빠른 650MHz로 데뷔하였고
이후 몇 차례의 공정 개선을 거쳐 최고 클럭 2.2GHz를 끝으로 K8 아키텍처에 자리를 내주게 됩니다.
K8은 K7에서 아키텍처의 하드웨어적인 변화보다는 소프트웨어적인 변화가 컸습니다. (64비트로의 확장)
K8은 전통적으로 메인보드 칩셋이 관장하던 메모리 컨트롤러 기능을 CPU에 내장함으로써
당시까지 출시되었던 어떤 CPU보다 높은 버스 대역폭과 낮은 지연시간을 보이며 큰 성능 향상을 이뤘습니다.
하지만 K8은 2006년 출시된 인텔의 코어 2 CPU에 압도당하며 최고 성능의 자리를 내놓게 됩니다.
7. Intel Netburst (Pentium 4) Microarchitecture
AMD 애슬론의 상업적 성공에는 CPU 자체의 뛰어난 성능도 한몫했지만
펜티엄 III 대비 애슬론의 높은 작동속도가 마케팅에 큰 이점으로 작용한 이유도 있습니다.
(펜티엄 III 최고클럭 1.4GHz vs 애슬론 최고클럭 2.2GHz)
이에 인텔에서는 오로지 작동 속도를 높이는 데 올인하여 깊은 파이프라인을 가진 펜티엄 4를 설계합니다.
펜티엄 4의 파이프라인은 총 20스테이지로, 펜티엄 III의 10스테이지보다 무려 두 배나 많습니다.
한 시대에 투입할 수 있는 트랜지스터 갯수는 제조공정의 한계로 무한정 늘어날 수 없기 떄문에
펜티엄 4는 각 파이프라인 단계마다 투입될 트랜지스터의 양을 감안해 백엔드를 간소화할 수밖에 없었습니다. 또한 파이프라인이 멈출 경우 엄청난 성능 저하를 초래하는 깊은 파이프라인 설계의 단점을 보완하기 위해
명령어를 끊임없이 백엔드에 공급할 수 있도록 인텔은 펜티엄 4의 프론트엔드에도 중대한 변경을 가합니다.
바로 프론트엔드의 바깥에 있던 L1-명령어 캐시를 프론트엔드 내부로 옮겨온 것입니다.

기존의 L1-명령어 캐시에는 디코드되기 전 상태의 명령어 스트림이 저장되지만,
펜티엄 4의 L1-명령어 캐시에는 Micro-operations (uops: 마이크로옵) 형태로 디코드된 명령어가 저장됩니다.
펜티엄 4의 깊은 파이프라인 구조상 파이프라인이 멈추면 엄청난 성능 저하를 초래하게 되는데
이를 방지하기 위해 캐시로부터 명령어를 가져오는 시간을 단축하기 위한 설계입니다.
인텔은 이러한 캐시 구조를 특별히 트레이스 캐시(Trace Cache)라고 합니다.
얼핏 디코드를 먼저 하나 나중에 하나 차이가 없을 것이라고 생각하기 쉽지만
캐시에 일단 저장된 명령어를 반복적으로 인출하게 되면 이야기가 달라집니다.
CPU가 저장 장치로부터 최초로 명령어를 가져올 때에는 다음과 같은 단계를 거칩니다.
- 기존: 캐시 -> 페치 -> 디코드 -> 제어 유닛 -> 백엔드 (5단계)
- 넷버스트: 페치 -> 디코드 -> 캐시 -> 제어 유닛 -> 백엔드 (5단계)
하지만 일단 캐시에 저장된 명령어를 인출할 때에는 아래와 같이 단계의 차이가 벌어집니다.
- 기존: 캐시 -> 페치 -> 디코드 -> 제어 유닛 -> 백엔드 (5단계)
- 넷버스트: 캐시 -> 제어 유닛 -> 백엔드 (3단계)
(다만 트레이스 캐시의 효율을 높이기 위해서는 캐시 적중률이 필수적으로 향상되어야 합니다)
명령어 스트림 (01010001... 따위의 2진수 수열) 이 비트 형태로 저장되는 여타의 캐시와 달리
트레이스 캐시는 마이크로옵 단위로 저장하는데, 펜티엄 4의 트레이스 캐시의 용량은 12,000uops 입니다.
이는 일반 캐시의 16~18KB 용량에 해당합니다.
그럼 이제 펜티엄 4의 백엔드를 보시겠습니다.

앞서 보았듯 펜티엄 4는 많은 트랜지스터를 깊은 파이프라인 구현에 투입한 댓가로 백엔드를 간소화했습니다.
(위의 그림에서 왼쪽 두번째 포트에 연결된 FPU는 부동소수점 연산을 수행하지 않고, 부동소수점 데이터 로드/스토어만 담당하는 일종의 메모리 접근 유닛입니다. 또한 같은 포트에 연결된 S-IU는 정수 수행 유닛이지만, 역시 정수 데이터 로드/스토어 기능도 함께 수행합니다)
P6 아키텍처의 5 이슈 백엔드에서 이슈 포트가 하나 줄어 한 클럭당 4개의 명령어가 보내지게 되었는데
이로 인해 줄어든 성능을 만회하기 위해 펜티엄 4는 단순 정수 유닛(S-IU)을 두 개로 늘리게 됩니다.
(일상적인 작업에서 복합 정수/부동소수점 명령어보다 단순 정수 명령어의 비중이 더 높기 때문이죠.)
또한 두 개의 S-U는 CPU 클럭 사이클의 라이징 / 폴링 엣지(rising / falling edge)모두에 수행이 가능해서
실질적으로 CPU 작동속도의 두 배로 작동하는 효과를 가져옵니다.
하지만 이러한 고속 S-IU에도 명령어가 제때 공급되지 않으면 속도상의 이점을 전혀 볼 수 없죠.
다시한번 프론트엔드(특히 트레이스 캐시)의 역할이 중요해지는 부분입니다.
출시 초기 펜티엄 4는 클럭이 낮은 펜티엄 III과 별반 다를 바 없는 성능으로 혹독한 비판을 받았습니다.
하지만 공정이 개선됨에 따라 작동속도가 2~3GHz 이상으로 올라가며 어느 정도 시장의 호응을 얻었습니다.
넷버스트 아키텍처 말기엔 파이프라인을 무려 31단계로 쪼개 오로지 클럭을 높이는 데 주력했으나
이 시기 들어 펜티엄 4의 높은 발열과 소비전력, 지나치게 낮은 클럭당 성능이 논란을 불러일으켰고
이에 인텔은 넷버스트 아키텍처를 폐기, 과거의 P6 아키텍처를 개량한 '코어' 아키텍처를 설계하게 됩니다.
넷버스트 아키텍처가 폐기되기 전까지 인텔은 10GHz 돌파를 목표로 하고 있었다고 합니다.
8. Intel Core / Nehalem Microarchitecture

코어는 AMD K6 / K7 아키텍처와 같이 동시에 6개의 명령어를 받을 수 있는 백엔드 구조를 가졌습니다.
단순 계산만으로도 백엔드에 동시에 4개의 명령어를 보낼 수 있는 넷버스트보다 50% 가량 빨라집니다.
또한 코어 2 들어서 SIMD 유닛의 데이터 전송폭이 128bit로 확대되면서, 128bit SSE 명령어를 한 사이클만에 처리하게 되어 기존보다 최대 두배까지 부동소수점 벡터 연산 성능이 향상되는 이점을 얻었습니다.
(기존의 부동소수점 유닛 및 SIMD 유닛의 데이터 전송폭은 80bit로, 128bit SSE 명령어가 들어올 경우 내부적으로 64bit 마이크로옵 두 개로 쪼개 두 사이클에 걸쳐 처리해야 했습니다. 위 그림은 128bit로 두배 확장된 SIMD 유닛을 나타내고 있습니다)
그 외에도 코어 아키텍처에서는 프론트엔드 부분에 중대한 변경이 가해져 CPU의 성능 향상에 일조했습니다.
이로써 코어 아키텍처가 적용된 첫 프로세서인 코어 2 듀오는 출시와 동시에 당대 최고의 CPU였던
AMD의 애슬론 64 X2의 성능을 완전히 압도하며, 만 7년 만에 최고 성능 CPU의 자리를 탈환했습니다.
코어 아키텍처를 발표하고 2년 뒤, 인텔은 코어 아키텍처를 개량한 네할렘 아키텍처를 발표했습니다.
기본적으로 백엔드의 구성은 코어와 동일하나, 프론트엔드와 메모리 구조에 약간의 변화가 있었습니다.
네할렘은 AMD가 K8에서 도입한 것처럼 CPU에 메모리컨트롤러를 내장하여 큰 성능 향상을 이뤘습니다.
9. AMD K10 / K10.5 Microarchitecture

7년간 누려온 성능상 우위를 인텔에게 뺏긴 뒤, AMD는 아키텍처를 혁신해 새로운 CPU를 만드는 대신
기존의 K7 / K8 아키텍처를 소폭 개량해 시장에 빨리 멀티코어 프로세서를 투입하려는 전략을 택하게 됩니다.
K10은 K8에 비해 아키텍처상의 큰 변화가 없어 인텔로부터 최고 성능 타이틀을 재탈환하는 데는 실패했지만
인텔이 코어 아키텍처에서 도입한 것과 마찬가지로 부동소수점/벡터 유닛의 대역폭을 128bit로 확대해
128bit 부동소수점 명령어(SSE)를 한 사이클만에 처리할 수 있게 되었습니다.
최초의 K10은 65nm 공정으로 제조되었고, 이후 45nm 공정으로 옮겨 (K10.5) 현재에 이르고 있습니다.
K10.5 역시 K10과 비교해 아키텍처 상의 변화점은 거의 없지만, 벡터 유닛에 연결된 포트가 하나 늘어
한 클럭당 최대 3개까지의 부동소수점 벡터 연산을 수행할 수 있게 되었습니다. (K10은 최대 2개)
또한 FP 스케줄러의 용량이 36uop에서 48uop으로 늘어 부동소수점 연산성능이 약 33% 가량 개선되었습니다.
2011년 새 아키텍처를 채용한 CPU가 발표되지만 그 후로도 K10은 존속해 32nm 공정까지 생산될 예정입니다.
10. Intel Sandy Bridge Microarchitecture

인텔은 네할렘 마이크로아키텍처를 발표한 지 2년만에 샌디 브릿지라는 새로운 아키텍처를 발표합니다.
샌디 브릿지의 백엔드는 코어/네할렘과 거의 동일하지만 AVX라는 새로운 벡터 유닛이 추가되었습니다.
AVX는 AMD가 개발한 FMA4 / XOP / CVT16 이란 명령어 세트와 인텔이 개발한 FMA3를 망라한 것으로
그 중 애초 AMD의 XOP는 SSE5라는 이름으로 K10 이후 개발될 아키텍처에 적용될 예정이었으나
K10 이후 AMD에서 새로운 CPU 아키텍처의 개발이 없었고, 인텔이 여기에 256bit 데이터 확장을 제안하며
2008년까지 양 사에 의해 최종적으로 개발이 완료, AVX란 이름으로 발표되게 됩니다.
SSE5의 특징은 기존 x86 명령어와 달리 3~4피연산자를 지원한다는 점인데, 기존엔 여러 사이클이 걸리던
곱셈-덧셈 혼합 연산(Fused Multiply-Add)을 한 사이클만에 완료할 수 있게 하는 중대한 변화입니다.
(FMA3, FMA4 역시 이름에서 알 수 있듯 Fused Multiply-Add에 관한 명령어 확장입니다)
이러한 3~4피연산자 지원은 x86 명령어 세트로서는 XOP에서 처음 도입되었지만 RISC에선 이미 쓰여 왔는데,
이 개념을 최초로 도입한 곳은 다름아닌 모토롤라입니다. (AMD와 K7 개발을 위해 제휴했던 회사이기도 하죠)
90년대 중반 모토롤라-IBM-Apple 3사는 RISC CPU 개발을 위한 카르텔인 AIM Alliances를 결성하였고
이들의 CPU인 POWER-6, G4, G5에 적용된 벡터 확장 명령어 세트인 Altivec이 3~4피연산자를 지원했습니다.
아직까지는 AVX를 지원하는 어플리케이션이 거의 없어 전세대 CPU와 큰 성능 차를 보이고 있지는 않지만
향후 최적화가 이뤄짐에 따라 과거 펜티엄 II -> 펜티엄 III만큼의 성능 차를 보일 것으로 전망됩니다.
11. AMD Bulldozer Microarchitecture
활발히 새로운 아키텍처를 도입한 경쟁사와 달리 AMD는 K10 이후 4년간 새로운 CPU의 발표가 없다시피 했고
그마저도 K10은 12년 전 개발된 K7 아키텍처의 마이너 업데이트에 불과해 변화가 절실한 상황이었습니다.
이에 AMD는 차기 아키텍처로 저전력에 주안점을 둔 Bobcat과 퍼포먼스용의 Bulldozer를 동시 개발해 왔고
지난 12년간의 모습과 전혀 다른, '바닥에서부터 새로(from scratch)' 설계한 아키텍처임을 공언하고 있습니다.
이 중 AMD의 차기 플래그십을 담당할 불도저 아키텍처에 대해 살펴보도록 하겠습니다.
우선 불도저는 기존의 CPU와 달리 칩 단위, 또는 코어 단위로 세는 것이 애매합니다.
불도저 CPU의 최소 단위는 '모듈'로, 1 불도저 모듈은 1코어로 볼 수도, 2코어로 볼 수도 있는 구조입니다.
구체적으로 프론트엔드는 1코어, 백엔드는 불완전-2코어로 볼 여지가 있으나 종합적으로 1코어에 가깝습니다.
다만 제조사에서는 1 불도저 모듈을 2코어로 홍보하고 있어 향후 이론의 여지가 발생할 수 있습니다.
(프론트엔드 구조에 대해서는 현대 CPU의 구조 <프론트엔드 편>을 읽어 주시기 바랍니다. ☞ 링크)
불도저의 백엔드 구조를 자세히 들여다보면 아래와 같습니다.

단일 프론트엔드에서 백엔드로 이어지는 포트는 12개로 사이클당 최대 12개의 명령어를 공급할 수 있으며 이 중 4개는 공유 부동소수점 스케줄러로, 나머지 8개는 각각 4개씩 따로 분화된 정수 스케줄러로 보내집니다.
이 분화된 정수 스케줄러 및 정수/메모리 유닛이 불도저 모듈 내부의 '독립된 코어'를 구성하는 단위가 됩니다.
각 '코어'는 정수 스케줄러로부터 4개의 명령어를 공급받으며 각각 2개의 정수 유닛/주소 생성 유닛을 가지는데 기존의 K7 ~ K10 까지의 설계와 비교하면 수행 유닛 수 대비 공급되는 명령어 개수가 두 배로 늘었습니다.
(기존은 3-이슈 정수 스케줄러에 각각 3개씩의 정수 유닛/주소 생성 유닛이 연결되어 있었습니다)
기존 아키텍처의 철학은 스케줄러에 명령어가 갑자기 몰릴 것을 대비해 수행 유닛을 넉넉히 두는 것이었다면
불도저에서는 극한 상황에서의 성능 피크치를 희생하는 것을 감수하고, 그 외 일반적인 경우에 한 사이클당 더 많은 명령어를 처리해 내는 것(=높은 연산량(스루풋: throughput)을 목표로 했다고 할 수 있습니다.
한편 두 '코어'가 공유하는 부동소수점/벡터 유닛 부분을 보면 우선 새로 등장한 AVX 유닛이 눈에 띕니다.
사실 불도저에 탑재된 벡터 유닛은 모두 128bit로 256bit AVX 명령어 포맷을 직접 지원하지는 않는 구조인데
AVX 명령어를 전송받았을 때 2개의 128bit SSE 유닛이 짝을 이뤄 한 사이클에 처리하거나 각 128bit SSE 유닛이 두 사이클에 걸쳐 처리하게 됩니다. 즉 사이클당 평균 1.5개의 AVX 명령어를 처리할 수 있는 것이죠.
다만 현재 AVX의 활용 영역이 거의 없는 관계로 'AVX를 지원한다'는 차원 이상의 의미는 없을 듯 합니다.
전체적으로 보았을 때, 1 불도저 모듈이 풀(full)로 가동되는 경우(=2스레드) 이를 단일 코어로 간주하면
역대 최대의 백엔드 대역폭을 가지는 단일 CPU가 됩니다. 그렇다면 싱글스레드 상황에서의 성능은 어떨까요?
불도저의 '2개의 코어'가 공유하는 자원을 모두 사용해 1개의 스레드를 처리한다고 가정할 때,
그 1스레드가 사용할 수 있는 백엔드의 자원은 아래와 같습니다.

절반으로 줄어든 정수 유닛은 기존의 K10 대비 67% 수준에 불과하지만 부동소수점 유닛은 133% 수준입니다.
즉 싱글스레드 성능에 있어서 불도저는 K10 대비 정수보단 부동소수점의 성능향상에 집중했다고 볼 수 있는데
많은 부동소수점 연산량을 요하는 멀티미디어 작업, 그 중에서도 게임이 멀티스레드에 최적화되지 않은 것을 감안하면 불도저는 전세대 대비 게이밍 성능이 크게 향상될 것으로 보입니다.
(※ CPU의 성능은 백엔드의 유닛 개수만으로 따질 수 없고, 프론트엔드의 구조 역시 대단히 중요합니다.
즉 여기서 유닛 개수만으로 정수 성능이 떨어질 것으로 예측한 것은 실은 논리의 비약을 포함하고 있습니다)
싱글스레드 단위에서 부족한 듯 보이는 정수 성능이 절실히 요구되는 분야는 서버 어플리케이션인데,
이런 프로그램은 사용환경의 특성상 싱글스레드보다는 멀티스레드 퍼포먼스에 민감한 경우가 많기 때문에
결과적으로 정수 유닛을 모듈당 '2코어'로 분화한것은 상당히 효율적인 전략입니다.
그리고 위 그림이 나타내는 '싱글스레드 불도저 모듈'은 단지 개념적인, 가상의 구조가 아니라
실제로 출시될 CPU 역시 각 모듈이 하나의 스레드만 처리할 경우에 대비한 고속화 전략을 채택하고 있습니다.
(1모듈이 2스레드를 처리할 때에 비해 1모듈이 1스레드만 처리할 때 작동클럭이 약 30%~35% 올라갑니다)
종합하면 불도저의 설계 철학은 아래의 3문장으로 요약됩니다:
1. 싱글 스레드에서 정수 성능의 피크치를 희생하더라도 스루풋을 늘리는 방향으로 가자.
2. 싱글 스레드에서 정수 성능보다는 부동소수점 성능을 늘리는 것이 우리의 관심사.
3. 정작 정수 성능이 절실히 필요한 곳은 서버. 멀티스레드 단위에서 정수 성능을 극대화하자.
이 설계 철학은 불도저의 프론트엔드 구조에서 더 명확히 드러나는데, 이건 다음 강좌에서 뵙겠습니다...^^
//
(아래 위젯은 티스토리의 크라우드펀딩 시스템인 '밀어주기' 위젯입니다. 100원부터 3000원까지의 범위 내에서 글쓴이에게 소액 기부가 가능합니다. 사견으로는 이러한 형태의 펀딩이야말로, 성공적으로 정착될 경우 이해관계자로부터 독립된 벤치마크가 지속가능해지는 원동력이 될 것이라 생각합니다. 제가 작성한 글이 후원할만한 가치가 있다고 여기신다면 밀어주기를 통한 후원을 부탁드립니다. 물론 글을 '가치있게' 쓰는 것은 오롯이 저의 몫이며, 설령 제 글이 '후원할 만큼 가치있게' 여겨지지는 못해 결과적으로 후원을 받지 못하더라도 그것이 독자 여러분의 잘못이 아니란 건 너무 당연해 굳이 언급할 필요도 없겠습니다. 저는 후원 여부와 관계없이 제 글을 읽어주시는 모든 독자분께 감사합니다.)
'Lecture & Column > cpu_lec_col' 카테고리의 다른 글
| 파이프라이닝의 이해 (22) | 2011.03.02 |
|---|---|
| 멀티스레딩 기술의 이해 (53) | 2011.02.05 |
| 현대 CPU의 구조 : 프론트엔드 편 (36) | 2011.01.22 |
| 오버클럭의 공학적 배경 (26) | 2011.01.14 |
| 현대 CPU의 구조 : 메모리 계층 구조와 성능 (9) | 2010.11.24 |